Top Contributors
Top Categories
Latest Posts
-
Bow down before the power of MCMC: Markov chain là gì.
Blog cũ, Blog mới.
Hôm nay, tôi rất hân hạnh vì được các bro rủ vào team AIIR để làm tác giả đóng góp các bài viết kỹ thuật.Càng vinh dự hơn khi là người đầu tiên mở màn cho blog, do đó tôi sẽ bắt đầu với một seri bài viết không tầm thường.
Lúc trước, tôi cũng đã từng viết blog cá nhân, cũng lười nên ít khi viết bài mới. Tuy nhiên bây giờ, blog đó sẽ chỉ là nơi chứa những bài viết mang tính cá nhân nhiều hơn; còn các bài viết kỹ thuật sẽ được đưa lên blog này; và tôi cũng sẽ không đưa các bài đã viết ở blog cũ lên đây renew. Các bạn nếu quan tâm có thể tham khảo tại Ngọc Sơn Bùi Văn Cường
Mở màn về seri bài viết.
Trong cái tên của blog này có liên quan đến AI, đây là thứ tôi ko thích lắm. Không phải vì không biết về nó, cũng không phải vì hiện nay xã hội gáy quá nhiều về AI mà ko hiểu j, mà là vì các thành viên trong nhóm chúng tôi đều hướng đến trở thành kỹ sư, chứ không đơn thuần chỉ hiểu biết 1 trong 2 thứ là algorithm hoặc engineering.
Do đó, seri bài viết này sẽ nói về một thứ rất quan trọng, và có ứng dụng trong cả Machine Learning và một chút liên quan đến Cryptography (vui thôi). Đó là MCMC (Markov chain Monte Carlo). Những ai học tập hay nghiên cứu về Machine Learning thì chắc chắn ko thể ko biết MCMC. Tuy nhiên để mà hiểu rõ mọi thứ về MCMC thì ko phải đơn giản; nhất là với một thanh niên kém giỏi Toán như tôi thì quá trình tìm hiểu về MCMC lại là 1 khoảng thời gian ko hề ngắn và đơn giản tí nào. Đọc ko biết bao nhiêu lần, nhưng cảm giác cứ luôn như này vậy!

May sao “cần cù bù siêng năng”, tôi cũng đã ngộ ra được vài phần về MCMC để tiếp tục có thể nghiên cứu về Machine Learning mà không bị thấy khó chịu khi phải cưỡi ngựa xem hoa.
Seri bài viết này tôi đã định viết lên blog cá nhân từ lâu rồi, nhưng cũng vì lười vs bận mà chưa viết được. Hôm nay cũng là mở màn luôn cho blog mới này của ae.
MCMC thật ra là j?
'MCMC' = str('MC' + 'MC')Yes, indeed, MCMC bao gồm 2 thành phần là MC (Markov chain) và MC (Monte Carlo). Vậy hẳn là kỹ thuật này có liên quan đến 2 thứ là Markov chain và cái thành phố Monte Carlo của Monaco. Đặt tên tài tình thật, theo như Wiki thì Monte Carlo là thành phố nổi tiếng với các sòng bài, khá là liên quan đến Xác suất thống kê. Còn Markov chain là một mô hình toán học do nhà toán học người Nga tên là Markov tìm ra. Lần đầu tiên chúng tôi được tìm hiểu về nó là trong môn Toán chuyên đề của Sư phụ tôi dạy hồi năm 3 đại học. Feeling amazing!
Tóm lại, MCMC là lớp các thuật toán lấy mẫu một cách continuous các phân phối xác suất dựa trên:
- Việc xây dựng MC - Markov chain nối từng thời điểm lấy mẫu.
- Kỹ thuật ra quyết định trong random walk liên quan đến cờ bạc ở thành phố MC - Monte Carlo.
Tại sao lại phải là MCMC?
Phân phối xác suất.
Mục đích của MCMC là lấy mẫu các phân phối xác suất! Lấy mẫu (sampling) một phân phối xác suất là thủ tục tính random để trả về giá trị của biến ngẫu nhiên ứng với phân phối xác suất đó. Ví dụ với phân phối Beta đi; Google phát là biết ngay hàm mật độ xác suất (PDF - Probability Density Function) của phân phối Beta được biểu diễn bởi công thức liên quan đến hàm Beta:
\[f\left(\theta|\alpha,\beta\right)=\frac{\theta^{\alpha-1}.(1-\theta)^{\beta-1}}{\Beta(\alpha,\beta)}\]Với \(Beta\) là hàm số phụ thuộc \(\alpha\) và \(\beta\) theo công thức:
\[\Beta\left(\alpha,\beta\right)=\frac{\Gamma(\alpha).\Gamma(\beta)}{\Gamma(\alpha+\beta)}\]Với \(\Gamma\) (đọc là Gamma) lại là một hàm số khác nữa phụ thuộc vào một biến \(n\) theo công thức:
\[\Gamma(n)=\int\limits_0^{+\infty}x^{n-1}.e^{-x}.dx\]May sao, với những người lười nhớ cũng như kém Toán như tôi chẳng hạn, Python đã có những thư viện hỗ trợ đến tận răng để giúp chúng ta lấy mẫu phân phối [$Beta$] mà ko cần phải nhớ một công thức toán học lằng nhằng nào trong các công thức trên cả! Công việc còn lại đơn giản chỉ là Google search “python numpy beta distribution”, sau đó copy code và run. Thế là ta có thể lấy mẫu phân phối $Beta$ bao nhiêu lần cũng được.
>>> import numpy as np >>> import matplotlib.pyplot as plt >>> x = np.random.beta(2,3,1000) >>> plt.hist(x, bins=100) >>> plt.savefig('beta.2.3.1000.png')Và đây là biểu đồ histogram thể hiện kết quả lấy mẫu 1000 lần phân phối $\Beta(\alpha=2,\beta=3)$ bằng đoạn Python script trên:
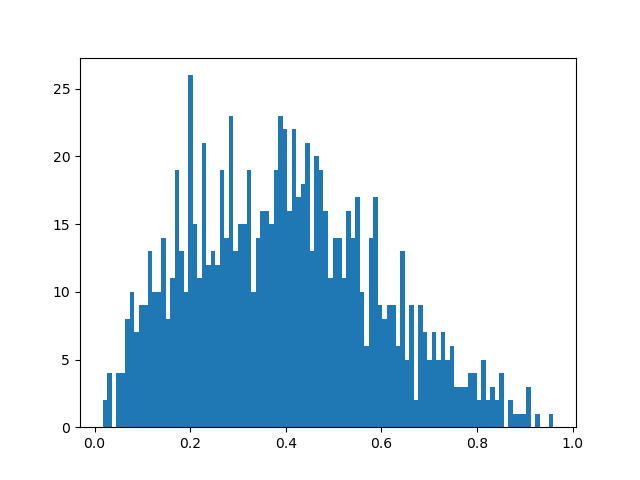
Nhìn qua ta thấy hình dạng hàm mật độ xác suất của hàm $\Beta(\alpha=2,\beta=3)$ này có vẻ là hình chuông (kiểu Gaussian), nhưng hơi bị lệch về phía bên trái (vì $\alpha < \beta$). Cách lấy mẫu này xuất phát từ chính công thức hàm mật độ xác suất của phân phối xác suất cần lấy mẫu, nên đương nhiên 1000 mẫu này - theo một thống kê nào đó - có thể coi là đại diện được cho phân phối $\Beta(\alpha=2,\beta=3)$. Nếu cần kiểm chứng, ta có thể vẽ đồ thị hàm $\Beta(\alpha=2,\beta=3)$ ra rồi so sánh hình dạng 2 biểu đồ với nhau là thấy rõ ràng ngay!
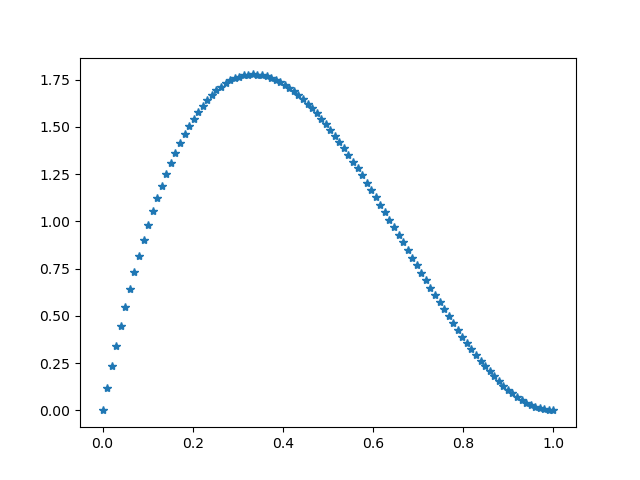
>>> import numpy as np >>> from scipy.stats import arcsine >>> import matplotlib.pyplot as plt >>> from scipy.stats import beta >>> x = np.linspace(0, 1.0, 100) >>> y = beta.pdf(x, 2, 3) >>> plt.plot(x, y, "*") >>> plt.savefig('beta.2.3.png')Và đương nhiên, kết quả sẽ ko nằm ngoài phán đoán của chúng ta, khi mà đường nối đỉnh của các bin trong biểu đồ histogram cũng có hình dạng na ná như hình dạng thật của đồ thị hàm $\Beta(\alpha=2,\beta=3)$.
MCMC ở đâu vậy?
Đúng vậy, MCMC - như đã nói - được dùng để lấy mẫu các phân phối xác suất cơ mà. Ta đã lấy mẫu $\Beta(\alpha=2,\beta=3)$ xong rồi mà đã cần biết MCMC là cái quái j đâu! Nhưng từ từ, cái khó bây giờ mới bắt đầu xuất hiện, nãy giờ chỉ là lũ creep thôi, giờ mới đến miniboss!
Trong thực tế tìm hiểu Machine Learning (theo hướng Generative model), ta thường rất ít khi được lấy mẫu mấy phân phối xác suất mà có công thức hàm mật độ xác suất rõ ràng như phân phối $\Beta(\alpha=2,\beta=3)$ kia! Thay vào đó, chúng ta hầu như sẽ gặp mấy tình huống kiểu thế này:
Trong Bayesian statistic, chúng ta sẽ phải đưa về việc tính xác suất hậu nghiệm bằng việc tính tích phân sau:\(p\left(\theta|x\right)=\frac{p\left(x|\theta\right).p(\theta)}{p(x)}\)
Với mẫu số được tính theo công thức xác suất toàn phần:\(p\left(x\right)=\int\limits_{\theta}p(\theta).p\left(x|\theta\right).d\theta\)
Trong phân số này thì tử số thường dễ tính, nhưng mẫu số thì sẽ khó tính vãi cả lúa nếu như tính tích phân kia với biến ngẫu nhiên nhiều chiều.Tôi đã đọc đi đọc lại cái nội dung kiểu kia ko biết bao nhiêu lần rồi, cứ chỗ nào nói về Bayesian Inference thì kiểu quái j chỗ đó cũng nói mấy câu kiểu này; và kèm theo đó là ko giải thích rõ ràng vì sao lại như thế! Đù má con cá!
Do đó, để có thể hiểu được ở mức thô sơ đủ để ko cưỡi ngựa xem hoa, tôi sẽ lấy một ví dụ thực tế như này. Trong vấn đề Topic Modeling, chúng ta phải tìm ra phân phối xác suất của topic (chủ đề) trong tập các document (văn bản) cho trước. Muốn vậy, ta cần phải tính toán xác suất thuộc topic z của từng word (từ ngữ) w trong từng doc. Vậy nôm na, ta phải tính $p\left(z|w\right)$. Tuy nhiên theo thủ tục của thuật toán LDA (Latent Dirichlet Allocation), thì ta sẽ lấy mẫu w từ z, chứ ko phải z từ w. Do đó xác suất trên được biến đổi theo công thức Bayes thành: \(p\left(z|w\right)=\frac{p\left(w|z\right).p(z)}{p(w)}=\frac{p\left(w|z\right).p(z)}{\int\limits_{z}p(z).p\left(w|z\right).dz}\) Ở đây, mỗi word w và topic z đều được biểu diễn dưới dạng một vector. Tính tích phân của hàm nhiều chiều thì phải đưa về tính tích phân nhiều lớp. Cụ thể trong trường hợp này, ta phải tính tích phân với số lớp bằng số lượng topic muốn xác định (tức là bằng số chiều của ko gian vector z chứa vector z). Nói tóm lại là rất khó tính.
Vì khó tính trực tiếp như vậy, nên người ta ko thể tìm ra chính xác biểu thức hàm phân phối xác suất $p(w)$ để mà thực hiện lấy mẫu. Lúc này thì MCMC xuất hiện như một vị thần, sẽ giải quyết được vấn đề lấy mẫu cái phân phối xác suất $p(w)$ kia mà ko cần phải tính chính xác công thức hàm mật độ xác suất! Tuy nhiên, đó là một câu chuyện khác khó hơn, liên quan đến vấn đề Topic Modeling, vượt qua phạm vi của chuỗi bài viết này. Do đó, để thể hiện được tác dụng của MCMC, tôi sẽ lấy một ví dụ dễ tiếp thu hơn nhiều.
Ko cần phải đi đâu xa, lấy ngay ví dụ ở hàm $\Beta(\alpha,\beta)$ thôi. Nhắc lại công thức mật độ xác suất của phân phối Beta, ta có: \(f\left(\theta|\alpha,\beta\right)=\frac{\theta^{\alpha-1}.(1-\theta)^{\beta-1}}{\Beta(\alpha,\beta)}\) Và như đã trình bày ở bài viết Gaussian là giới hạn cuối cùng, thì ở phân thức trên, tử số chính là kernel (hạt nhân) của hàm mật độ xác suất, còn nghịch đảo của mẫu số chính là NormConst (Normalizing Constant - hằng số chuẩn hóa) của hàm mật độ xác suất. Và 2 thành phần này có quan hệ với nhau theo công thức: \(NormConst =\frac{1}{\int\limits_{0}^{1}Kernel}=\frac{1}{\int\limits_{0}^{1}\theta^{\alpha-1}.(1-\theta)^{\beta-1}.d\theta}\) Bây giờ, để tính cái tích phân ở dưới mẫu kia, ta sẽ đi chứng minh công thức: \(\Beta\left(\alpha,\beta\right)=\frac{\Gamma(\alpha).\Gamma(\beta)}{\Gamma(\alpha+\beta)}\Leftrightarrow\Gamma(\alpha).\Gamma(\beta)=\Gamma(\alpha+\beta).\Beta(\alpha+\beta)\) Với hàm Beta được định nghĩa theo công thức: \(\Beta(\alpha,\beta)=\int\limits_0^1{x^{\alpha-1}.(1-x)^{\beta-1}.dx}\) Theo định nghĩa hàm Gamma, ta có: \(\Gamma(n)=\int\limits_0^{+\infty}x^{n-1}.e^{-x}.dx\) \(\Rightarrow\Gamma(\alpha).\Gamma(\beta)=\left(\int\limits_0^{+\infty}x^{\alpha-1}.e^{-x}.dx\right)\left(\int\limits_0^{+\infty}y^{\beta-1}.e^{-y}.dy\right)\) \(=\int\limits_0^{+\infty}\int\limits_0^{+\infty}x^{\alpha-1}.y^{\beta-1}.e^{-(x+y)}.dx.dy\) Ta đã bắt đầu thấy mùi của hàm $\Gamma(\alpha+\beta)$ ở $e^{-(x+y)}$ rồi đấy. Bây giờ phải tiến hành đổi cận sao cho 1 biến vẫn từ $0\rightarrow+\infty$, còn một biến phải chạy từ $0\rightarrow1$. Hơn nữa phải có 1 biến mới là tổng của 2 biến cũ. Do đó ta đặt $x=uv, y=u(1-v)$.
Với $x,y\in[0;+\infty]\Rightarrow u\in[0;+\infty],v\in[0;1]$, và $x+y=u$
Đạo hàm từng phần theo ma trận Jacobi, ta được: \(\frac{\partial(x,y)}{\partial(u,v)}=\begin{vmatrix}v&u\\1-v&-u\end{vmatrix}=-uv-u+uv=-u\) Vì $u>0$, do đó $dx.dy=\left|\frac{\partial(x,y)}{\partial(u,v)}\right|.du.dv=u.du.dv$
Thay vào tích phân cũ, ta được: \(\Gamma(\alpha).\Gamma(\beta)=\int\limits_0^1\int\limits_0^{+\infty}{u^{\alpha-1}.v^{\alpha-1}.u^{\beta-1}.(1-v)^{\beta-1}.e^{-u}}.u.du.dv\) \(=\left[\int\limits_0^1{v^{\alpha-1}.(1-v)^{\beta-1}.dv}\right].\left[\int\limits_0^{+\infty}{u^{\alpha+\beta-1}.e^{-u}.du}\right]=\Beta(\alpha,\beta).\Gamma(\alpha+\beta)\) Phù, gõ latex toát mồ hôi! Cuối cùng thì chúng ta cũng chứng minh được công thức hàm Beta, từ đó có thể tính hàm Beta dựa trên hàm Gamma. Nói tóm lại, là ta có thể tính được NormConst của Kernel của phân phối Beta. Do đó có thể biểu diễn phân phối Beta về dạng một hàm số tường minh, nên việc lấy mẫu sẽ ko phải vấn đề!
Tuy nhiên, bây giờ giả dụ là ta ko thể tính được NormConst thì sao? Bên trên là hên có nhà Toán học nào đó chứng minh được công thức liên hệ giữa Beta và Gamma, thì mới tính được rõ công thức hàm mật độ xác suất của phân phối Beta thôi. Nhỡ đâu cái tích phân toàn miền xác định của Kernel ko thể tính được thì sao? Khả năng này kiểu j cũng xảy ra thôi. Nếu ko xảy ra thì ta cứ giả dụ là nó sẽ xảy ra đi. Tức là chúng ta chỉ biết kernel, mà ko biết NormConst. Giả sử NormConst là một hằng số $C$ nào đó mà ta ko biết. Khi đó hàm mật độ xác suất của phân phối Beta sẽ có dạng: \(f\left(\theta|\alpha,\beta\right)=C.\theta^{\alpha-1}.(1-\theta)^{\beta-1}\) Vấn đề đặt ra là làm sao mà vẫn có thể lấy mẫu được phân phối Beta khi mà công thức hàm mật độ xác suất lại ko tường minh thế kia (vì ta ko biết $C$)! Đúng vậy, đây là lúc MCMC phát huy tác dụng của nó. Mình gõ latex mệt rồi, seri sẽ tiếp tục ở các bài sau nhé!
Kết.
Trong bài mở đầu seri về MCMC này, mình mới chỉ dừng lại ở nguồn gốc của thuật ngữ MCMC cũng như nêu ra khó khăn trong việc lấy mẫu của các phân phối xác suất ko có công thức hàm mật độ ở dạng tường minh. Đây là điểm cốt lõi khiến MCMC có thể phát huy tác dụng tuyệt vời của nó.
Ở bài viết sau, tôi dự định sẽ nói về Markov chain cũng như giải quyết vấn đề lấy mẫu phân phối Beta khi chỉ biết kernel của nó bằng việc sử dụng một thuật toán lấy mẫu trong họ các thuật toán của MCMC. Phần này lan man hơi nhiều biến đổi Toán học khá ít liên quan; nhưng phần sau sẽ là cốt lõi để chúng ta có thể hiểu được MCMC hoạt động thế nào (ít nhất là 1 thuật toán lẫy mẫu trong họ MCMC).
-
Mối nguy hiểm tiềm tàng của các thuật toán Dynamic routing trong việc xây dựng Forwarding Table - Lý thuyết Đồ thị.
Hôm nay tôi mới tìm ra nguyên nhân dẫn đến 1 con bug mà tôi đau đầu trong suốt mấy ngày. Con bug này xuất hiện trong chương trình mô phỏng sự hoạt động của các thuật toán định tuyến trong Mạng liên kết nói riêng và trong Lý thuyết đồ thị nói chung.
-
Tôi năm tuổi 24+
Ngày cuối Thu năm ấy, hắn 24+ tuổi.
-
Kỹ Sư là 'bậc thầy kỹ thuật', ko phải là 'lập trình viên'
Hôm qua, Sư Phụ hẹn tôi lên nói chuyện về dự định đồ án cũng như nghiên cứu. Đồ án thì xong từ thời cổ lỗ sĩ rồi, chủ yếu là công việc nghiên cứu. Ngoài ra cũng có mấy cậu sv năm cuối được hẹn lên gặp để làm đồ án tốt nghiệp. Qua cuộc nói chuyện giữa Sư Phụ và các cậu sv đó, Sư Phụ đã chỉ ra 2 sai lầm của mọi người về mặt tư tưởng rằng: AI/Machine Learning cũng chỉ là 1 phần trong 1 kỹ sư thôi, và cũng ko phải là phần cốt lõi tạo nên chất của kỹ sư đó! Đừng vì nó hot mà cố tìm cách sử dụng nó để tạo ra thứ mà ko ai cần! Kỹ sư ko phải loại người mà hầu hết xã hội (thị trường lao động) đang nghĩ! Quá lạm dụng từ “kỹ sư” đẫn đến xã hội hiểu và đánh giá sai vai trò của 1 người thực sự là kỹ sư. Về điều đầu tiên, hiển nhiên rồi! Trong vài năm gần đây, AI (Artificial Intelligence) - hay còn gọi là “trí tuệ nhân tạo” - là từ khóa hot nhất trong ngành. Hot đến nỗi các bác nông dân ở quê cũng biết có thuật ngữ này tồn tại. Nhưng thật sự thì như vậy là hay? Ko, chả hay ho con khỉ j cả! Khi 1 chủ đề mà được lan tỏa bởi những người ko hiểu biết thật sự về nó, thì sẽ xảy ra hiện tượng “tam sao thất bản”. Y hệt như hiện tượng vanishing gradient hay exploding gradient hay xảy ra trong quá trình gradient propagation khi ta huấn luyện mạng nơ-ron vậy.
-
Setting Up A Small Video Conferencing Server
Update (6 April 2020): Having just updated my server, it appears that the latest version of Jitsi leads to some issues. I ended up reinstalling using the quick install guide, which worked without any issues . Best to go with that for now!
-
Kiwifruit
Kiwifruit (often abbreviated as kiwi), or Chinese gooseberry is the edible berry of several species of woody vines in the genus Actinidia.
-
Apples
An apple is a sweet, edible fruit produced by an apple tree.
-
Markdown Test
Today we gonna going through some systax of markdown and how to write your blog in markdown format.
-
Lorem Ipsum
Lorem ipsum dolor sit amet
Lorem ipsum dolor sit amet ut paulo aperiam signiferumque quo. Quaeque pertinacia mnesarchum te vel.